Or – Resolving the ColdFusion Content is not allowed in prolog Error.
If you’ve tried to consume web services with ColdFusion, you may have run into this issue when attempting to use the returned XML. I’ve seen this crop up when simply pulling in an RSS feed as well. Often there are some strange characters at the beginning of the XML response. We can see the problem if we use Firefox to browse to the Authorize.net web service:

Here you can see Authorize.net is sending back XML describing an error (we didn’t post any data to the webservice, after all) but FireFox is throwing an error about the XML itself. These same characters that are tripping up FireFox will also cause problems when you try to run the text through the ColdFusion XML parser. The error is not very intuitive, either – Content is not allowed in prolog. This error comes from the embedded Java SAX XML parser.
You can see the characters here after I try to hit the web service via ColdFusion and then dump the cfhttp variable:
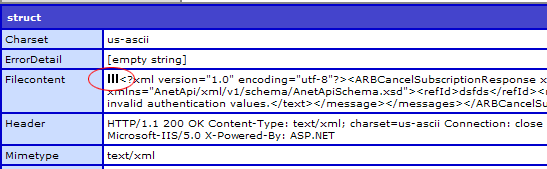
If I try to run that text through the XMLParse() function I’ll get:
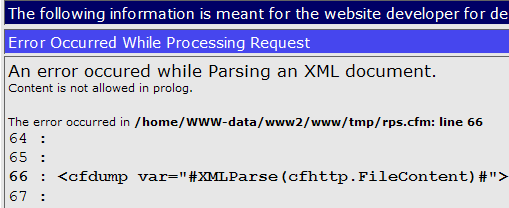
These funny characters are showing up because we are not using UTF-8, which is the character set the response is encoded with. We can see this because the very first line of the XML packet contains this: encoding="utf-8".
We can fix the problem in ColdFusion by adding the charset="UTF-8" attribute to our cfhttp tag. Now if I dump the cfhttp variable I see:
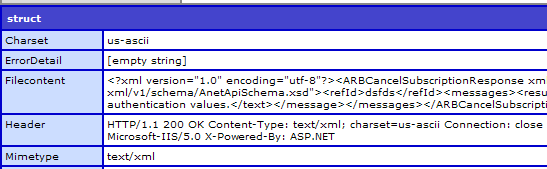
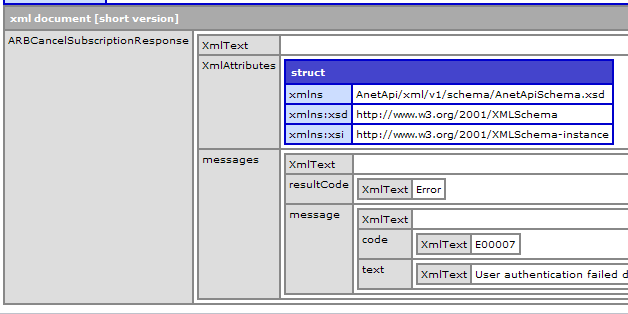
Great! Now lets run it through XMLParse():
We still get the error! Lets take a closer look at the cfhttp.FileContent variable. I’ll put asterisks around it so we can see exactly where it starts and stops.
<cfoutput>*#cfhttp.fileContent#*</cfoutput>
Results in:
*ErrorE00007User authentication failed due to invalid authentication values.*
Nothing odd there (the tags don’t show up, just the content between the tags). But viewing the page-source in my browser reveals something:
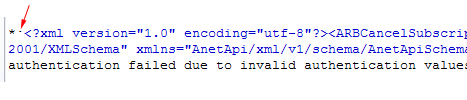
See that little dot? There is a funny character still in there! This character is a Byte Order Mark, or a BOM. If you want to read more about what a BOM is, see this Wikipedia article. A BOM was traditionally used in a file to indicate if the byte order was little-endian or big-endian. Its only purpose in a UTF-8 stream is just to indicate that the following content is in UTF-8. When properly decoded (which we did when we added the charset attribute to the cfhttp tag) the BOM does not usually show up, thats why I had to view-source to even be able to see it. It’s ascii code is 65279, which is a Zero Width No-Break Space – hence usually not seen. Now that we know what it is, we can remove it:
<cfif Asc(Left(cfhttp.fileContent,1)) EQ 65279>
<cfset returnedXML = Right(cfhttp.fileContent,Len(cfhttp.fileContent)-1)>
</cfif>The result now parses into an XML object properly:

mark kruger says:
Ryan, awesome stuff. You do a great job of organizing and sequencing information.
19 July 2007, 9:48 pmKevin R. says:
Hello,
I ran into this exact issue when parsing XML returned from a QuarkXpress Server ‘deconstruct’ (it returns a XML document with all of the data used in conjunction with the referenced Quark file).
I kept thinking it was my code, but it all worked perfectly with other XML documents.
I used your fix and life was good!
Best regards,
15 October 2007, 3:37 pmKevin R.
http://www.MyOwnLabels.com
George says:
THANK YOU THANK YOU THANK YOUTHANK YOU!!!!! You are awesome!!!!!!!!!!!!!
18 October 2007, 5:17 pmCarolyn says:
Thanks so much – this helped me “parse the unparceable feed”!
1 April 2008, 1:54 pmCM says:
Just repeating the thanks — very helpful!
8 October 2008, 2:20 pm